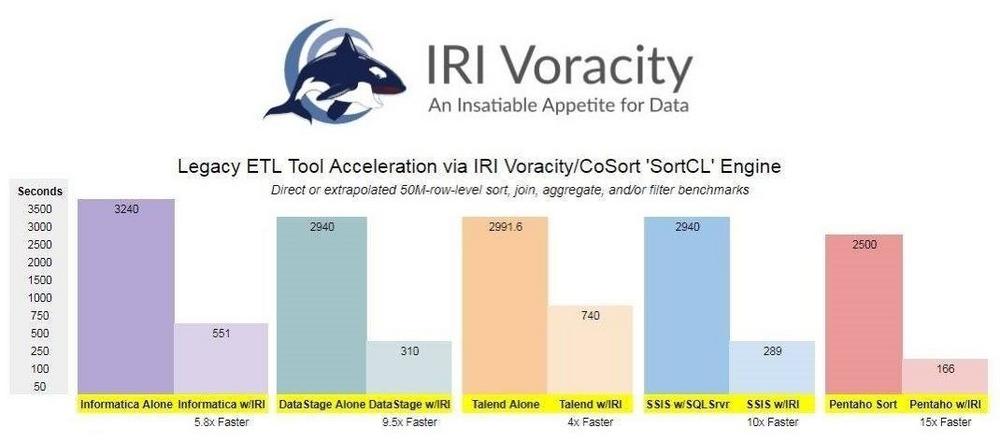
❌ Schnelle Datentransformation ❌ Wachsendes Data Warehouse bewältigen = ohne zusätzlicher Hardware, Spark oder Hadoop ❗
- eine teure Parallelverarbeitungs-Edition
- Entnahme von Datenbank- oder Systemressourcen von Dritten
- eine komplexe, schwer zu wartende Hadoop-Umgebung
- eine 6 oder 7-stellige Hardware-Appliance oder Server-Upgrades
- das Problem auf eine noch teurere Datenbank zu übertragen
Es sind die großen Sortier-, Joint- und Aggregationsaufträge, die zu lange dauern können. Auch nachfolgende Aufgaben wie das Laden, Analysieren oder BI-Displays leiden. Und diese E-, T- und L-Schritte werden typischerweise in separaten Schritten, I/O-Durchgängen, Produkten oder ständig wechselnden Cloud-Konfigurationen durchgeführt.
Lösungen: Wenn Sie andere ETL- oder ELT-Software verwenden, können IRI-Extraktions- und Transformationsprogramme wie FACT oder CoSort – oder die IRI Voracity ETL- und Datenmanagement-Plattform, die sie unterstützt – innerhalb anderer ETL-Tools ausgeführt werden, die auf Unix-, Linux- oder Windows-Hardware laufen.
Optimieren Sie Sortier-, Joint- und Aggregationstransformationen in Inormatica, DataStage, Talend, Pentaho, ODI und anderen Tools mit der SortCL-Engine im CoSort Produkt oder der Voracity-Plattform. Viele SortCL-Aufträge können auch nahtlos in Hadoop ausgeführt werden und werden mit anderen Tools auf API- oder Skriptebene aufgerufen, z.B. in Kalido, ETI, Software AG Natural, SAS und TeraStream.
Verwenden Sie die Metadaten und Workflows die Sie haben und rufen Sie die IRI-Software einfach von Ihrem Tool aus auf, um die Geschwindigkeit zu erhöhen und/oder Entladen, Datentransformationen und Operationen wie:
- Sortierungen
- Joins
- Aggregate
- Lookups
- Perl-kompatible reguläre Ausdrücke
- Datentyp- und Dateiformatkonvertierungen
- Feld-/Spaltenverschlüsselung und Maskierung
- Detail-, Delta- (CDC) und Summenberichte
- Pivoting von Zeilen und Spalten
- Slowly Changing Dimensions
- Generierung von Testdaten
Sie können IRI-Jobs auch von der Shell aus (als Batch-Ausführung oder ETL-Tool-Befehl) über API oder Eclipse GUI aufrufen und Daten bei Bedarf über Dateien, Pipelines oder Prozeduren hin und her fließen lassen. In der GUI-Umgebung der IRI Workbench können Sie die einzelnen Job-Spezifikationen oder komplette ELT- oder ELT-Flüsse erstellen, die CoSort (und FACT) mit Ihren Quellen und Zielen verbinden.
Erwin (AnalytiX DS) und Meta Integration Model Bridge (MIMB) Software oder Dienste können auch Metadaten, die in gängigen ETL-Tools (wie Informatica’s.xml und DataStage.dsx Repositories) definiert sind in gleichwertige Voracity-Daten- (und/oder Job-) Spezifikationen konvertieren, wenn Sie diese Mappings in Voracity umplatzieren möchten um Geld und Zeit zu sparen. Diese automatische Metadatenreplikation bewahrt Ihre bestehenden Designinvestitionen, erleichtert die Schaffung von Arbeitsplätzen und reduziert die Migrationskosten.
Kontaktieren Sie uns gerne für einen gezielten Benchmark von Ihrer benutzerdefinierten Umgebung!
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()
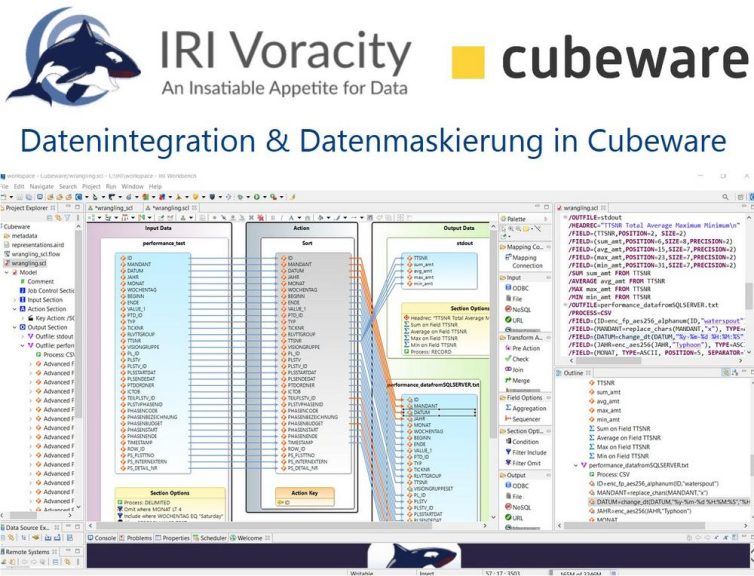
❌ Cubeware ❌ Push von Datenintegration und optional GDPR-anonymisierte Daten für BI-Analysen in Cubeware Cockpit ❗
In früheren Artikeln im Business Intelligence (BI)-Abschnitt haben wir beschrieben, wie der Umgang mit Daten mit der SortCL-Engine im Datenmanipulationsprodukt IRI CoSort und der Datenverwaltungsplattform Voracity die Zeit bis zur Datenvisualisierung und damit zu verwertbaren Erkenntnissen in BI-Tools verkürzt. In diesem Artikel werden die Vorteile des Data Wranglings hervorgehoben, die Voracity für Analysen in der Cubeware-Plattform bietet.
Voracity ist zwar sehr schnell im Umgang mit Daten und verfügt über ein breites Spektrum an Datenmanipulations- und Datenschutzfunktionen, es fehlt jedoch ein Onboard-Visualisierungs- und Dashboarding-Tool. Hier kommt Cubeware ins Spiel. Umgekehrt steigert Voracity für Anwender von Cubeware Software den Wert ihres Importer-Prozesses durch schnelle, konsolidierte Datentransformation, Bereinigung und Maskierung.
Cubeware bietet mit dem Importer ein grafisches ETL-Tool zur Konsolidierung von Daten aus verschiedenen Quellsystemen mit umfassenden Transformationsprozessen an, das viele Funktionalitäten mit Voracity gemeinsam hat.
Warum brauche ich dann Voracity? Für mehr Geschwindigkeit bei der Vorbereitung von großen Big Data Dateien, zusätzliche Datenqualitätsmerkmale und datenzentrische Sicherheitsfunktionen (PII-Klassifizierung, Discovery und Maskierung) zur Einhaltung der GDPR etc.
Zunächst verwendet Voracity die SortCL-Engine, um Daten schneller zu integrieren und zu verarbeiten als der Cubeware Importer und die meisten ETL-Tools auf dem Markt. SortCL ist ein schnelles, aufgabenkonsolidierendes Datenverarbeitungsprogramm für strukturierte und halbstrukturierte Quellen, das Speicher, Threads und E/A optimiert. Es läuft auf Windows- und Linux/Unix-Befehlszeilen lokal oder in der Cloud.
SortCL-Jobs werden in einfachen 4GL-Job-Skripten spezifiziert, die auch in einer freien grafischen IDE namens IRI Workbench, die auf Eclipse™ basiert, entworfen und verwaltet werden können. SortCL-Programme sind nicht nur leicht verständlich, sondern unterstützen auch eine Vielzahl von Datenmanipulations-, Mapping-, Munging-, Maskierungs- und Mining-Funktionen für Hunderte von Anwendungsfällen in den Bereichen Datenverarbeitung, Schutz, Prototyping und Präsentation.
SortCL kann Voracity eine Vielzahl von Datenqualitätsfunktionen unterstützen! Die Datenvalidierungsfunktionen können die Datenqualität verbessern, z. B. durch die Schaffung von Bedingungen zum Testen auf leere Werte, groß- oder kleingeschriebene Werte, alphabetische und numerische Werte, druckbare Werte und vieles mehr. Es kann auch Datensätze filtern, die bestimmte Bedingungen, Bereiche oder Mengenschwellen erfüllen. GDPR-Konformität kann durch SortCL-unterstützte Daten-‚Schilde‘ erreicht werden, die PII wie Löschung, Verschlüsselung, Schwärzung und Pseudonymisierung usw. maskieren.
Vor allem aber können alle oben genannten Aktivitäten, die mit ETL, Datenqualität und Maskierung zu tun haben, gleichzeitig und im selben Job-Skript und E/A-Durchlauf durchgeführt werden, was zu einer erheblichen Zeitersparnis bei der Entwicklung und Ausführung von Jobs führt. SortCL kann auch benutzerdefinierte 2D-Detail- und Zusammenfassungsberichte erstellen, um einen schnellen Überblick über die Daten zu bieten und sicherzustellen, dass alles korrekt erscheint, bevor Cockpit mit den Übergaben gefüttert wird, die es für die schnelle Anzeige benötigt.
Fazit: Der größte Vorteil von Voracity ist die schnelle und robuste Verarbeitung von Flat-Files. Wenn es in der Lage ist, einen großen Prozentsatz von Datensätzen aus einer sehr großen Datei herauszufiltern, kann sein SortCL-Programm einen schnellen Datentransfer von Datei zu Datenbank ermöglichen. Datentransformation, Validierung, Bereinigung, Maskierung und Neuformatierung sind alles unterstützte Funktionen, die in einem SortCL-Skript und E/A-Durchlauf kombiniert werden können.
Im Allgemeinen würden SortCL-Skripte von Datei zu Datenbank beim Schreiben einer großen Anzahl von Datensätzen in die Datenbank zu langsameren Ergebnissen führen als Cubeware. SortCL kann jedoch die Eingabe von Flat-Files schneller verarbeiten und sie dann auf viel kleinere Untermengen von Datensätzen filtern, die für eine Datenbank gebunden sind.
Beim Lesen aus einer Datenbank und beim Schreiben in eine Flat-File kann die SortCL-Engine einige Geschwindigkeitsvorteile bieten. Ein von Cubeware zur Verfügung gestellter Benchmark ergab einen Durchschnitt von 5m:32s, um ähnliche Filterungen und Transformationen durchzuführen, die SortCL in 2m:11s durchführte. Die Eingabe für diesen Benchmark war Microsoft SQL Server, und die Ausgabe war eine durch Semikolon getrennte Textdatei.
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()
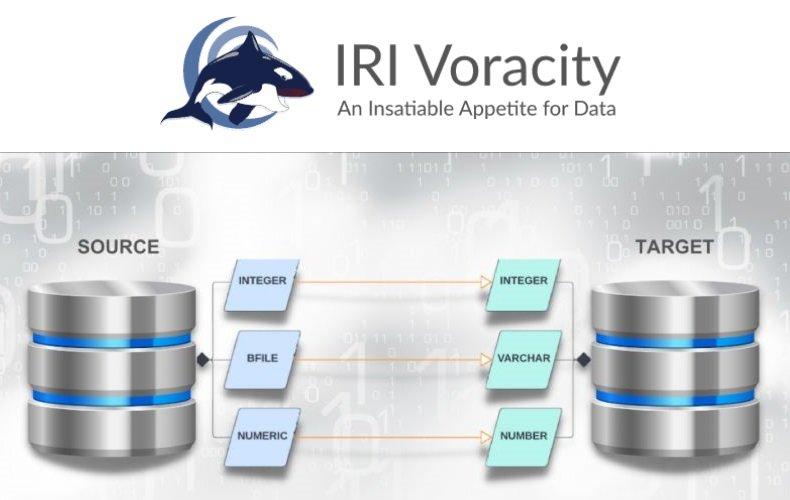
❌ Datenmapping ❌ Unterschiedliche Quell- und Zieldatentypen bei Datenintegration und Datenmigration automatisch angleichen ❗
Wenn nach Abschluss einer Aufgabe, wie z. B. der Maskierung mehrerer Tabellen in IRI FieldShield, im Zielschema noch keine Tabellen für die maskierten Daten vorhanden sind, müssen vorab DDL-Skripte (Data Definition Language) zur Erstellung der Tabellen erstellt werden.
Nehmen wir nun an, dass sich die Quell- und Zieltabellen in Datenbanken verschiedener Anbieter befinden. Es kann zu Fehlern in der DDL kommen, weil der Assistent, der die Skripte generiert, auf einen Datentyp stößt, der in einem Anbieter vorhanden ist, aber nicht im anderen.
An diesem Punkt wird ein Standarddatentyp verwendet – oft Varchar -, was nicht die beste Lösung ist und den Benutzer zwingt, die Skripte zu überprüfen und zu ändern. Dies kann ein zeitaufwändiger Prozess sein, und wenn der Benutzer nicht aufpasst, kann es zu einem Datenverlust führen.
Mit der Implementierung des neuen Assistenten für die Datentypzuordnung können IRI-Workbench-Benutzer festlegen, welche Datentypen verwendet werden sollen, wenn sie von einer Datenbank zu einer anderen wechseln.
Die grafische Benutzeroberfläche von IRI Workbench basiert auf Eclipse und wird zur Erstellung von Job-Skripten verwendet, die die Bewegung und Bearbeitung strukturierter Daten durch kompatible IRI-Produkte ermöglichen. Die gesamte in diesen Skripten spezifizierte Arbeit wird zur Laufzeit durch das Back-End-Datenverarbeitungsprogramm SortCL ausgeführt.
Überblick über Data Type Mapping: Die Einstellungen für die Datentypzuordnung finden Sie im Abschnitt IRI unter Einstellungen. Die erste Ansicht bietet Informationen über die erstellten Zuordnungen und ermöglicht verschiedene Optionen wie das Hinzufügen neuer Zuordnungen, das Bearbeiten vorhandener Zuordnungen, das Entfernen und das Importieren/Exportieren.
Die Tabelle hat vier Spalten, darunter Quelle und Ziel, die die Namen der DB-Profile enthalten, die beim Einrichten der JDBC-Verbindungen erstellt wurden. Dies sind die gleichen Namen, die Sie in der Ansicht Datenquellen-Explorer sehen sollten.
Die Spalte Name enthält eindeutige Namen für Datentyp-Maps, die einen Kontext für die Verwendung dieser Maps in verschiedenen Workbench-Assistenten liefern können. Aus diesem Grund müssen die Namen eindeutig sein.
In der Spalte Standard können Sie angeben, welche Zuordnung standardmäßig verwendet wird, wenn Jobassistenten DDL-Skripts erstellen. Wenn der Standard nicht ausgewählt ist, kann der Benutzer trotzdem eine Map verwenden, wenn die Quell- und Ziel-DB und die Version mit der im Assistenten verwendeten Quell- und Ziel-DB übereinstimmen.
Alle technischen Details finden Sie hier im ausführlichen technischen Blog-Artikel!
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()
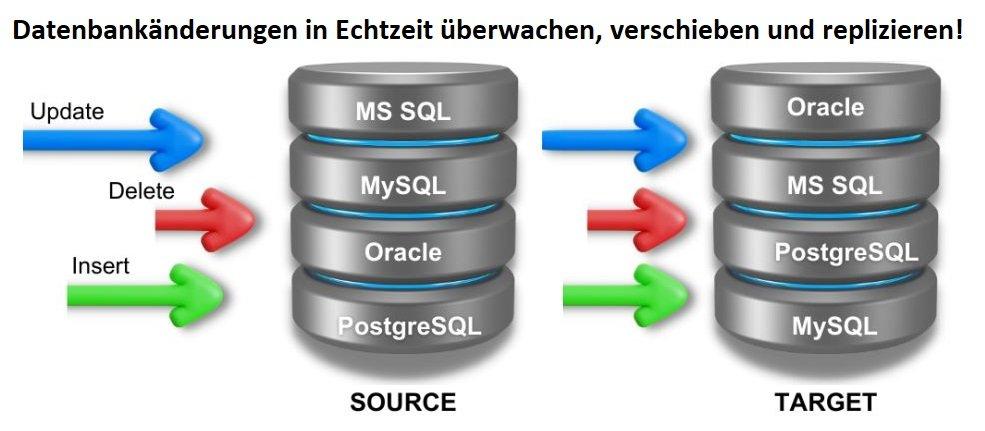
❌ Change Data Capture ❌ In Echtzeit auf Änderungen in der Datenbank reagieren mit bspw. Datenreplikation an nachgelagerte Ziele ❗
Was ist IRI Ripcurrent? Ripcurrent ist der Name einer von IRI entwickelten Java-Anwendung, die die eingebettete Debezium-Engine und die Streaming-Funktion des SortCL-Programms von IRI CoSort kombiniert, um in Echtzeit auf Datenbank-Änderungsereignisse zu reagieren, indem Daten an nachgelagerte Ziele repliziert werden, optional mit Transformationsregeln (z. B. PII-Maskierung), die konsequent auf der Grundlage der Klassifizierung der Daten angewendet werden.
Ripcurrent lässt sich mit Debezium integrieren, um Änderungen von verschiedenen DBs zu verfolgen. Ripcurrent bündelt Debezium-Konnektoren für MySQL, SQL Server, PostgreSQL und Oracle. Debezium unterstützt MongoDB, DB2 und Vitess, aber es ist mehr Arbeit erforderlich, um Ripcurrent für diese zu unterstützen.
Ripcurrent veranlasst SortCL automatisch, auf eingefügte, aktualisierte oder gelöschte Datenzeilen zu reagieren. Dadurch kann eine Reihe gleichwertiger Ziele (wahrscheinlich in einer niedrigeren Umgebung) mit den Quelltabellen synchronisiert und optional konsistente Transformationen auf Feldebene (wie Maskierung) auf die Daten angewendet werden.
Ripcurrent ist ein nahtloses Analogon zu diesem Ansatz für die Verarbeitung von Änderungen an Flat Files in Echtzeit und eine Alternative zu diesem Ansatz, um geänderte DB-Daten inkrementell zu verschieben und zu maskieren.
IRI Ripcurrent kann Änderungen bei jedem Einfügen, Aktualisieren oder Löschen von Zeilen in allen Tabellen einer Datenbank erkennen, mit Ausnahme von Tabellen oder Schemata, die aufgrund der an Ripcurrent übergebenen Konfigurationseigenschaften herausgefiltert wurden.
Zusätzlich werden auch andere Datenbank-Änderungsereignisse, wie z.B. die Änderung der Struktur einer Tabelle, von IRI Ripcurrent überwacht und aufgezeichnet. Nur Datenbank-Änderungsereignisse, die eine Änderung, Hinzufügung oder Löschung von Daten in einer Tabelle beinhalten, veranlassen IRI Ripcurrent dazu, auf dieses Ereignis zu reagieren.
Warum IRI Ripcurrent verwenden? Die Möglichkeit, Daten in Datenbank-Tabellen in andere Datenbank-Tabellen oder Dateien zu replizieren und/oder zu maskieren, wird von IRI-Software seit langem unterstützt. Dies geschieht in der Regel über IRI Workbench, die grafische Benutzeroberfläche für alle IRI-Produkte zur Verwaltung von (strukturierten) Daten.
Der "Schema Data Class Job Wizard" in IRI Workbench – bei dem Daten in einem Schema gesucht und in Datenklassen gruppiert werden – kann mit Maskierungsregeln kombiniert werden. Aus dem Assistenten wird eine Batch-Datei oder ein Shell-Skript generiert, um in FieldShield-Skripten definierte Massenmaskierungsoperationen auszuführen.
Wenn jedoch Änderungen an der Datenbank vorgenommen werden, gibt es keine einfache Möglichkeit, die Änderungen zu replizieren, ohne das Batch-/Shell-Skript erneut auszuführen. Und wenn der Datenbank zusätzliche Tabellen oder neue Spalten zu bestehenden Tabellen hinzugefügt wurden, werden diese ignoriert, es sei denn, der Assistent wird erneut ausgeführt, um ein neues Batch-/Shell-Skript und die entsprechenden IRI FieldShield-Skripts für den Vorgang zu generieren.
Die Notwendigkeit, mit Datenbank-Änderungen synchron zu bleiben, ist die Motivation für die Entwicklung von IRI Ripcurrent. Für diejenigen, die das/die nachgelagerte(n) Ziel(e) mit einer Quell-Datenbank synchron halten wollen, z. B. zu Testzwecken, bietet Ripcurrent die Funktionalität eines Datenbank-Maskierungsauftrags der Datenklasse, jedoch auf dynamische Weise.
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()
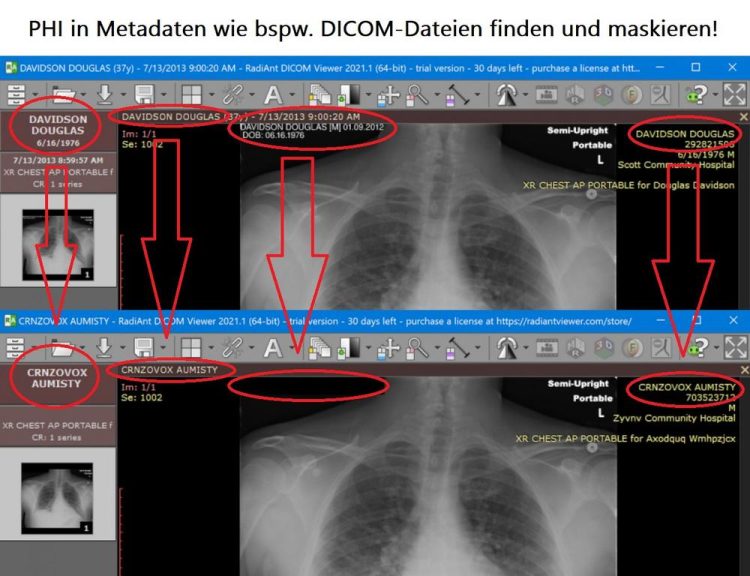
Patientendaten schützen ❌ Kritische Gesundheitsdaten in bspw. DICOM-Dateien automatisch finden und via Datenmaskierung schützen ❗
Mit Hunderttausenden von medizinischen Bildgebungsgeräten die im Einsatz sind, ist DICOM einer der am weitesten verbreiteten Nachrichtenstandards im Gesundheitswesen weltweit; Milliarden von DICOM-Bildern werden derzeit für die klinische Versorgung verwendet. Dieser Artikel beschreibt die Suche und De-Identifizierung von geschützten Gesundheitsinformationen (Protected Health Information, PHI) in DICOM-Metadaten und -Bildern mit Hilfe des Datenmaskierungstools IRI DarkShield und seiner Remote Procedure Call (RPC)-API für Dateien im Besonderen.
DICOM (Digital Imaging and Communications in Medicine) ist ein Standard für die Kommunikation und Verwaltung medizinischer Bilddaten und zugehöriger Daten. DICOM ist in fast allen Geräten der Radiologie, der kardiologischen Bildgebung und der Strahlentherapie (Röntgen, CT, MRI, PET, Ultraschall usw.) und zunehmend auch in Geräten anderer medizinischer Bereiche wie der Augenheilkunde und der Zahnmedizin implementiert.
DICOM definiert einzelne Dateien (in der Regel mit der Dateierweiterung .dcm), die eine eindeutige binäre Struktur aufweisen, die aus einer Kopfzeile und einem Datensatz mit einer Liste von Attributen besteht. Die Attribute enthalten Informationen über den Scan, wie z. B. den Patientennamen. Das letzte Attribut sind die eigentlichen Pixeldaten (Bilddaten) des Scans.
DICOM definiert auch eine Verzeichnisstruktur, in der Scans nach Patient, Studie und Serie geordnet sind. Diese Verzeichnisstruktur enthält Metadaten im CSV-Format an der Wurzel des Verzeichnisses.
DICOM-Dateien können aufgrund ihrer einzigartigen binären Struktur weder mit einem Texteditor bearbeitet noch mit einem typischen Bildbetrachter angezeigt werden.
Einzelne DICOM-Dateien enthalten eine Liste von Attributen. Zu den Attributen gehören Informationen über den Scan wie Patientenname, Geburtsdatum, Krankenhausname usw. sowie die Pixeldaten des Scans als letztes Attribut in der Sequenz. Einige Attribute sind optional, und alle können mit einem Tag gekennzeichnet werden.
Ein DICOM-Anzeigeprogramm zeigt in der Regel die Pixeldaten als Bild an, wobei die anderen Attribute über das Bild gelegt werden, obwohl diese anderen Attribute eigentlich von den Pixeldaten selbst getrennt sind. Die anderen Attribute sind immer noch Teil einer DICOM-Datei, aber nicht Teil der Pixeldaten. Es ist möglich, dass DICOM-Dateien eingebrannten Text enthalten, der in die Pixeldaten eingebettet ist.
Gezielter Datenschutz: Maskierung sensibler DICOM-Daten!
Die DarkShield-API für Dateien bietet nun eine Lösung für die Suche und Maskierung sensibler Attribute in einer DICOM-Datei, die auf einigen der bereits in der API vorhandenen Funktionen zur Dateiverarbeitung aufbaut, einschließlich HL7- und X12-EDI-Dateien.
Pixeldaten sind nur eines von vielen Attributen, die in einer DICOM-Datei enthalten sein können, und werden von anderen Attributen getrennt, die Schlüssel- oder Quasi-Identifikatoren wie Patientenname, Geburtsdatum und Krankenhaus enthalten können. DarkShield durchsucht alle Attribute, die nicht Teil der Pixeldaten sind.
Ein DICOM-Verzeichnis kann CSV-Metadaten in der Wurzel des Verzeichnisses enthalten, wie in der folgenden Abbildung dargestellt. Ein aufrufendes Programm kann dieses Verzeichnis durchlaufen und die CSV-Metadaten sowie die DICOM-Dateien an die DarkShield Files API senden.
Zusätzlich kann eine Reihe von Black Boxes in einem Dateimasken-Kontext angegeben werden, um bekannte Teile der Pixeldaten, die möglicherweise sensible Informationen in eingebranntem Text enthalten, zu schwärzen. Die Höhe, Breite sowie die X- und Y-Koordinaten jeder Blackbox können in der Konfiguration angegeben werden.
Beispiel für Datenmaskierung: Demoprogramm auf GitHub!
Ein auf GitHub verfügbares Demoprogramm demonstriert, wie der Inhalt eines DICOM-Verzeichnisses mithilfe der DarkShield-API maskiert werden kann. In diesem Programm wird ein ganzes Verzeichnis durchlaufen, um die CSV-Metadaten, Ordnernamen und einzelne DICOM-Dateien zu durchsuchen und zu maskieren. Das resultierende maskierte DICOM-Verzeichnis wird in einen separaten Ordner geschrieben.
Diese DICOM-Dateien werden zusammen mit anderen in der Verzeichnisstruktur, den Metadaten im Stammverzeichnis des DICOM-Verzeichnisses und den Ordnernamen durchsucht und maskiert. Alle sensiblen Informationen, die durch Suchabgleiche und Maskierungsregeln definiert sind, werden einheitlich behandelt. Jeder Suchmatcher ist mit einem Datentyp verknüpft, und jeder Datentyp wird auf der Grundlage der mit dem jeweiligen Matcher verbundenen Maskierungsregeln maskiert.
Umfassende Kontrolle: Überprüfung der Such- und Maskierungsergebnisse!
Die DarkShield-API gibt Suchanmerkungen als Teil ihrer Antwort zurück, wenn einer der Suchendpunkte aufgerufen wird. Außerdem werden die Ergebnisse der Maskierung als Teil der Antwort auf Maskierungsendpunkte zurückgegeben. Die Maskierungsergebnisse und Suchkommentare liegen in einem benutzerfreundlichen JSON-Format vor, das in BI-Tools aggregiert werden kann, um Einblicke in den Inhalt zu erhalten.
Beispielsweise können die gefundenen Übereinstimmungen mit sensiblen Daten und die Suchabgleicher, die diese Übereinstimmungen gefunden haben, zusammengefasst und auf visuelle Weise angezeigt werden. Die Visualisierung ist eine intuitive Methode, um Einblicke in diese Ergebnisse zu gewinnen, insbesondere wenn sie sehr umfangreich sind.
Die Überprüfung der Visualisierung von Annotationen und maskierten Ergebnissen kann helfen zu bestätigen, dass die Ergebnisse den Erwartungen entsprechen. Weitere Informationen, die in den Suchkommentaren und maskierten Ergebnissen enthalten sind, umfassen den Dateinamen, alle fehlgeschlagenen Maskierungsergebnisse und die Stelle in der Datei, an der die sensiblen Daten gefunden wurden.
Fazit: Einfach zu integrierende Lösung!
DICOM ist ein wichtiger Standard für die Speicherung personenbezogener Daten und Bilder im Gesundheitswesen, aber die De-Identifizierung von DICOM-Dateien kann aufgrund ihrer Komplexität eine schwierige Aufgabe sein. Dennoch müssen Datenschutzgesetze wie die im Rahmen des HIPAA erlassenen befolgt werden, um die PHI in den von Ihnen kontrollierten Datenquellen und -silos, einschließlich DICOM-Dateien, zu de-identifizieren oder zu anonymisieren.
Geldstrafen und ein geschädigter Ruf sind die Folge von Verstößen gegen PHI-Daten. Die DarkShield-API bietet jetzt eine effektive, einfach zu integrierende Lösung, um diese Herausforderungen und Vorschriften gleichzeitig zu bewältigen.
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: +49 (6073) 711403
Fax: +49 (6073) 711405
E-Mail: amadeus.thomas@jet-software.com
![]()
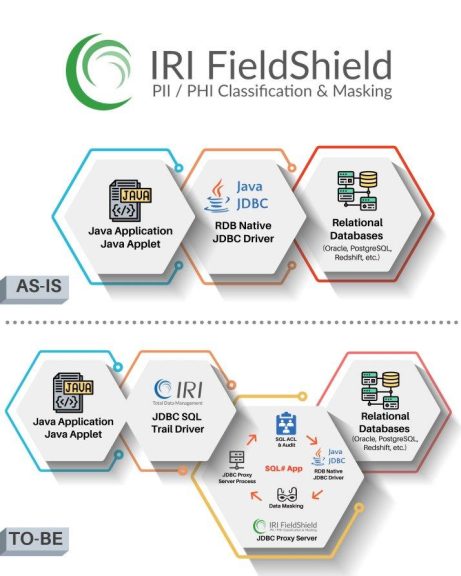
❌Proxy-basierte Datenmaskierung❌ Dynamische Datensicherheit bei Datentransaktion zwischen einer Anwendung und einer Datenbank ❗
Andere IRI-DDM-Optionen umfassen: API-aufrufbare FieldShield-Funktionen, die in C/C++/C#-, Java- oder .NET-Programme eingebettet sind; Echtzeit-FieldShield-Funktionen, die in SQL-Prozeduren eingebettet sind, die maskierte Ansichten erstellen; und die dynamische Demaskierung von statisch maskierten Tabellen für autorisierte Benutzer.
Das hier vorgestellte proxy-basierte System verwendet einen zweckmäßigen, datenbankspezifischen "JDBC SQL Trail"-Treiber in Verbindung mit einer Konfigurations- und Verwaltungs-Webanwendung namens SQL Sharp (SQL#). Alle technischen Details finden Sie hier im Blog-Artikel, datenzentrierte Sicherheit lohnt sich!
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: +49 (6073) 711403
Fax: +49 (6073) 711405
E-Mail: amadeus.thomas@jet-software.com
![]()
❌ TDM ❌ Eine funktionierende und bezahlbare Testdatenmanagement-Strategie für genügend realistische Testdaten ❗
Ziel des Testdatenmanagements (TDM) ist es, die Erzeugung von Testdaten zu systematisieren und deren Qualität, Sicherheit und Nutzen zu verbessern. TDM ist zu einem IT-Imperativ geworden. Laut dem InfoSys-Whitepaper "Test Data Management, Enabling Reliable Testing through Realistic Test Data:
"Testteams müssen nicht nur exakte Testmethodiken befolgen, sondern auch die Genauigkeit der Testdaten sicherstellen. Sie müssen auch sicherstellen, dass die Tests die Produktionssituationen korrekt widerspiegeln, sowohl funktional als auch technisch."
Die richtigen Testdatensätze zu haben, ist in vielen Situationen wichtig – zum Beispiel:
- Anwendungen und Softwareprogramme benötigen Daten, mit denen ihre Funktionalität validiert und ihre Kapazität unter Stress getestet werden kann
- Neue Hardware- und Software-Plattformen benötigen konsistente Datensätze zum Benchmarking ihrer Leistung
- Für den Betrieb von sehr großen Datenbanken (VLDB) und Enterprise Data Warehouse (EDW)-Prototypen werden Testdaten benötigt, die die Produktionsstrukturen und -beziehungen beibehalten, um Last- und Abfrageszenarien richtig zu simulieren
Regressionstests in diesen Umgebungen erfordern Testdaten, die:
- bereit sind, an den richtigen Stellen und in den richtigen Formaten
- sicher sind, so dass sie den Datenschutzgesetzen entsprechen
- vollständig sind, d. h. gute, schlechte und ungültige Datenwerte enthalten
- realistisch aussehen und transformationsfähig sind
- groß, für Simulationen von "Big Data"-Anwendungen
- richtig verteilt, um natürliche Vorkommnisse zu reflektieren
- referenziell korrekt, um die Abfrageintegrität zu wahren
Eine praktikable, gut überprüfte TDM-Strategie ist der beste Weg, um sicherzustellen, dass die realistischsten Testdaten zur Verfügung stehen. Die Artikel in dieser Serie umreißen strategische Überlegungen, die den meisten Anwendern dienlich sein werden und verweisen auf Taktiken im IRI RowGen-Paket zur Testdatenerzeugung.
Dies ist der Eröffnungsartikel, dem eine 4-stufige Serie folgt. Klicken Sie hier für den nächsten Artikel, Schritt 1: Zielsetzung und Teambildung
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()
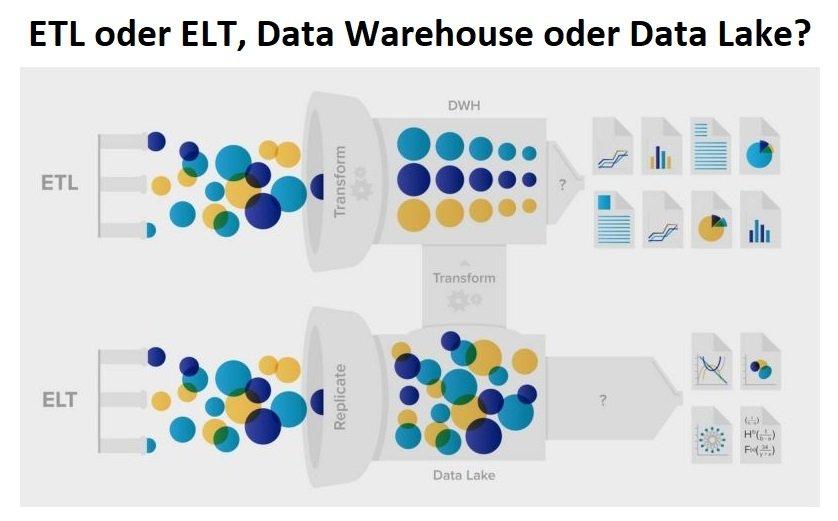
❌ ETL vs. ELT ❌ Die Prozesse der Datenintegration und des Data Staging bzw. der Datenaufbereitung effizienter gestalten❗
Bei ETL-Vorgängen (Extrahieren, Transformieren, Laden) werden Daten aus verschiedenen Quellen extrahiert, separat transformiert und in eine DW-Datenbank und möglicherweise andere Ziele geladen. Bei ELT werden die Extrakte in eine einzige Staging-Datenbank eingespeist, die auch die Umwandlungen übernimmt.
ETL ist nach wie vor weit verbreitet, da der Markt mit bewährten Anbietern wie Informatica, IBM, Oracle – und IRI mit Voracity, das FACT (Fast Extract), CoSort- oder Hadoop-Transformationen und Bulk Loading in derselben Eclipse-GUI kombiniert – floriert, um Daten zu extrahieren und zu transformieren. Dieser Ansatz verhindert, dass Datenbanken, die für die Speicherung und den Abruf von Daten (Abfrageoptimierung) konzipiert sind, mit dem Overhead einer groß angelegten Datentransformation belastet werden.
Mit der Entwicklung neuer Datenbanktechnologien und Hardware-Appliances wie Oracle Exadata, die Transformationen "in a box" verarbeiten können, kann ELT jedoch unter bestimmten Umständen eine praktische Lösung sein. Die Isolierung der Staging- (Laden) und der semantischen (Transformieren) Schicht bietet zudem besondere Vorteile.
Sehen Sie in diesem Artikel alle Vorteile und Nachteile, differenziert gelistet nach ETL und ELT.
In der Folge entstehen hybride Architekturen wie ETLT, TELT und sogar TETLT, mit denen versucht wird, die Schwächen der beiden Ansätze zu beheben. Diese scheinen jedoch die ohnehin schon komplizierten Prozesse noch weiter zu verkomplizieren. Es gibt wirklich kein Patentrezept, und viele Datenintegrationsprojekte scheitern an der Last der SLAs, der Kostenüberschreitungen und der Komplexität.
Aus diesen Gründen hat IRI Voracity entwickelt, um Daten über das CoSort SortCL-Programm in bestehende Dateisysteme oder Hadoop-Fabrics ohne Neucodierung zu integrieren. Voracity ist die einzige ETL-orientierte (aber auch ELT-unterstützende) Plattform, die beide Optionen für externe Datentransformationen bietet. Neben einem hervorragenden Preis-Leistungs-Verhältnis bei der Datenbewegung und -manipulation bietet Voracity:
- erweiterte Datentransformation, Datenqualität, MDM und Reporting
- Slowly Changing Dimensions, Change Data Capture, Datenföderation
- Datenprofilierung, Datenmaskierung, Testdatengenerierung und Metadatenmanagement
- einfache 4GL-Skripte, die Sie oder Eclipse-Assistenten, Diagramme und Dialoge erstellen und verwalten
- nahtlose Ausführung in Hadoop MR2, Spark, Spart Stream Storm und Tez
- Unterstützung für erwin Smart Connectors (Konvertierung von anderen ETL-Tools)
- native MongoDB-Treiber und Verbindungen zu anderen NoSQL-, Hadoop-, Cloud- und Legacy-Quellen
- eingebettete Reporting-, Statistik- und Vorhersagefunktionen, KNIME- und Splunk-Anbindungen sowie Datenfeeds für Analysetools.
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()

❌ Schutz von/in Dark Data ❌ Gezielte Datenmaskierung von Namen in unstrukturierten Quellen wie PDF, MS Office-Dokumenten, Bildern oder Textdateien ❗
Da es sich bei vielen Entitäten wie Personennamen oder Adressen um persönlich identifizierbare Informationen (PII) handelt, verwendet IRI DarkShield NER, um solche Daten zu finden und zu maskieren. Während die Kenntnis des Namens einer Person allein vielleicht kein allzu großes Risiko darstellt, erhöht sich in Kombination mit anderen sensiblen Daten das Risiko, dass diese Person zum Ziel von Cyberkriminellen wird, wenn der Datensatz angegriffen wird.
IRI DarkShield unterstützt bereits seit Jahren den Import und das weitere Training von OpenNLP-Modellen zum Auffinden und Maskieren von benannten Entitäten. Neu in der DarkShield RPC API 2022 ist jedoch die Unterstützung für moderne Tensorflow und PyTorch NER Modelle. Dies ist eine bedeutende Verbesserung gegenüber dem ersten Satz schneller, aber weniger NER-Modelle auf Basis von OpenNLP.
NER-Modelle, einschließlich solcher aus Quellen wie dem Hugging Face Model Hub. Allein von diesem Hub sind NER-Modelle in über 100 Sprachen verfügbar. Viele dieser Modelle nutzen die Vorteile der relativ neuen Transformer-Architektur für maschinelles Lernen, um die Trainingszeiten zu verkürzen und die Genauigkeit zu verbessern.
Um den Transformers Search Matcher mit der DarkShield-API zu verwenden, empfehlen wir ein System mit einem Grafikprozessor, um die Inferenz der meisten Modelle zu beschleunigen (in der Regel um mindestens das 20-fache). Die DarkShield-API lädt beim Start des Servers automatisch die für den Transformers-Matcher erforderlichen Abhängigkeiten herunter.
Modelle werden entweder als lokales Verzeichnis oder aus dem Hugging Face Model Hub angegeben. Bei direkter Angabe aus dem Hugging Face Model Hub sollte das Python-Skript model_util.py aus dem Ordner plankton/utils vorher ausgeführt werden, um das Modell herunterzuladen. Diesem Skript können die Argumente des Modells und des Tokenizer-Namens (oft derselbe wie der Modellname) übergeben werden.
Wir werden die Erkennung von benannten Entitäten in englischen, türkischen und japanischen Texten anhand von drei verschiedenen NER-Modellen demonstrieren, die alle im Hugging Face Model Hub verfügbar sind. Hier finden Sie den detaillierten technischen Blog-Artikel!
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()
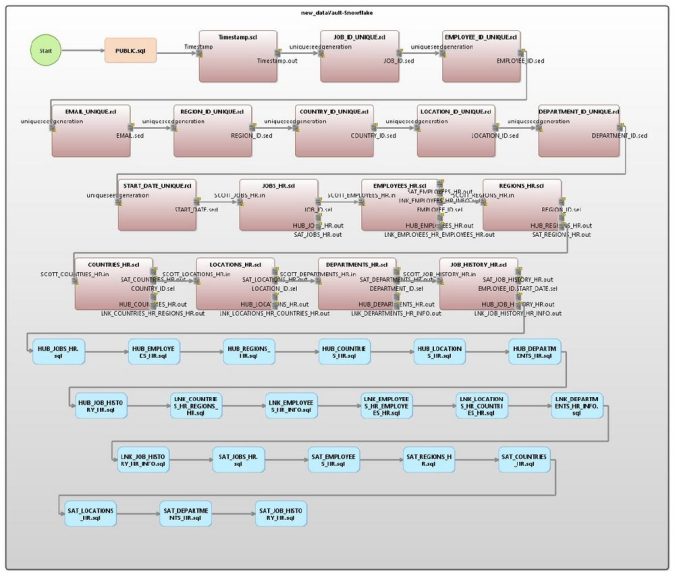
❌ Data Vault für Data Warehouse ❌ Datenmigration von RDB-Datenbankmodell in eine Data Vault 2.0 Architektur – der hybride Ansatz ❗
Alle Optionen erstellen das Entity Relationship Diagram (ERD) für die Ausgaben. Die erste Option erzeugt nur die vollständige DDL und ERD. Die zweite Option erstellt eine DDL für Tabellen, die noch nicht existieren, und erstellt außerdem Jobskripte zum Laden der Daten aus den Quelltabellen in die neuen Zieltabellen. Die dritte Option erstellt eine DDL für Tabellen, die nicht existieren, und lädt die neuen Tabellen mit zufällig generierten Testdaten. Dieser Artikel behandelt Option drei.
Laut Dan Lindstedt, dem Erfinder des Data Vault, "ist der Data Vault ein detailorientierter, historisch nachverfolgender und eindeutig verknüpfter Satz normalisierter Tabellen, die einen oder mehrere Funktionsbereiche des Unternehmens unterstützen.
Data Vault ist ein hybrider Ansatz, der das Beste aus der 3. Normalform (3NF) und dem Sternschema umfasst … [es] ist eine Datenintegrationsarchitektur; eine Reihe von Standards und definitorischen Elementen oder Methoden [dafür, wie] Informationen innerhalb eines RDBMS-Datenspeichers verbunden werden, um sie sinnvoll zu nutzen."
Im DV2-Standard gibt es drei Arten von Tabellen. Ein Hub enthält die eindeutigen Geschäftsschlüssel. Ein Link definiert die Beziehungen zwischen den Geschäftsschlüsseln. Ein Satellit enthält den Kontext (Attribute) der Tabelle. Ein Satellit kann entweder ein Kind einer Hub- oder einer Link-Tabelle sein.
In jeder dieser Tabellen wird ein Hash der Rohdaten des Schlüssels als Primärschlüssel der neuen Tabelle verwendet. Jede Tabelle enthält auch die Quelle der ursprünglichen Daten und einen Ladezeitstempel für die historische Verfolgung. Ein Satellit enthält auch einen Endzeitstempel und eine optionale Hash-Differenz zur Verfolgung von Änderungen an den Datensätzen.
Der "Voracity Data Vault Generator Wizard" verwendet die vorhandenen Primär- (PK) und Fremdschlüssel (FK) als Ausgangspunkt für die Organisation der neuen Tabellen. Die Standardwerte pro Tabelle sind wie folgt:
- Ein Knotenpunkt für jeden PK-Schlüssel (einschließlich zusammengesetzter Schlüssel).
- Ein Link für jeden selbstreferenzierenden FK.
- Ein Link für jede Gruppe von FKs (ohne die selbstreferenzierenden Schlüssel).
- Ein Satellit auf dem Hub, wenn die Tabelle null FKs enthält.
- Ein Satellit auf dem Link, wenn mindestens ein FK existiert.
In diesem Beispiel werden sieben verknüpfte Tabellen verwendet, die Personaldaten darstellen. Nachfolgend ist die ERD für die Quelltabellen dargestellt. Alle technischen Details dazu sind hier im Blog-Artikel zu finden.
Weltweite Referenzen: Seit über 40 Jahren nutzen unsere Kunden wie die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram,.. aktiv unsere Software für Big Data Wrangling und Schutz! Sie finden viele unserer weltweiten Referenzen hier und eine Auswahl deutscher Referenzen hier.
Partnerschaft mit IRI: Seit 1993 besteht unsere Kooperation mit IRI (Innovative Routines International Inc.) aus Florida, USA. Damit haben wir unser Portfolio um die Produkte CoSort, Voracity, DarkShield, FieldShield, RowGen, NextForm, FACT und CellShield erweitert. Nur die JET-Software GmbH besitzt die deutschen Vertriebsrechte für diese Produkte. Weitere Details zu unserem Partner IRI Inc. hier.
JET-Software entwickelt und vertreibt seit 1986 Software für die Datenverarbeitung für gängige Betriebssysteme wie BS2000/OSD, z/OS, z/VSE, UNIX & Derivate, Linux und Windows. Benötigte Portierungen werden bei Bedarf realisiert.
Wir unterstützen weltweit über 20.000 Installationen. Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: 06073-711403
Fax: 06073-711405
E-Mail: amadeus.thomas@jet-software.com
![]()