❌ Testdaten für Data Vault ❌ Data Vault Generator-Assistent für realistische Testdaten und sicheres TDM ❗
Alle Optionen erstellen das Entity Relationship Diagram (ERD) für die Ausgaben. Die erste Option erzeugt nur die vollständige DDL und ERD. Die zweite Option erstellt eine DDL für Tabellen, die noch nicht existieren, und erstellt außerdem Jobskripte zum Laden der Daten aus den Quelltabellen in die neuen Zieltabellen. Die dritte Option erstellt eine DDL für Tabellen, die nicht existieren, und lädt die neuen Tabellen mit zufällig generierten Testdaten. Dieser Artikel behandelt Option drei.
Laut Dan Lindstedt, dem Erfinder des Data Vault, "ist der Data Vault ein detailorientierter, historischer Tracking- und eindeutig verknüpfter Satz normalisierter Tabellen, die einen oder mehrere funktionale Geschäftsbereiche unterstützen.
Data Vault ist ein hybrider Ansatz, der das Beste aus der 3. Normalform (3NF) und dem Sternschema umfasst … [es] ist eine Datenintegrationsarchitektur; eine Reihe von Standards und definitorischen Elementen oder Methoden [dafür], wie Informationen innerhalb eines RDBMS-Datenspeichers verbunden werden, um sie sinnvoll zu nutzen."
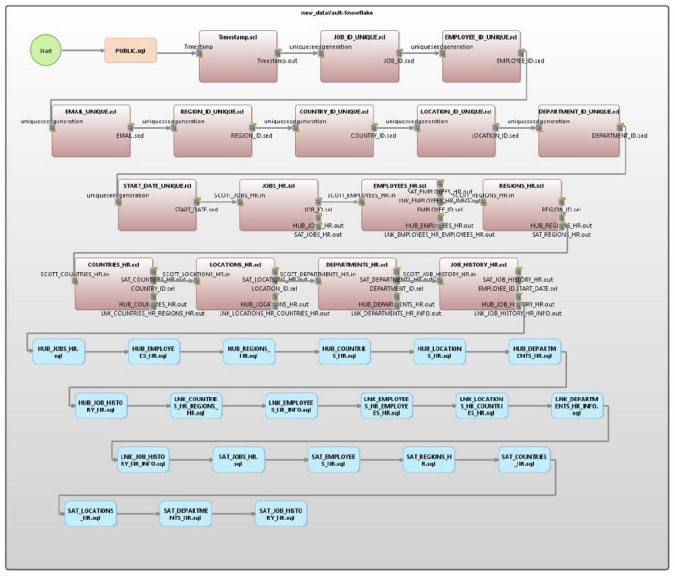
Im DV2-Standard gibt es drei Arten von Tabellen. Ein Hub enthält die eindeutigen Geschäftsschlüssel. Ein Link definiert die Beziehungen zwischen den Geschäftsschlüsseln. Ein Satellit enthält den Kontext (Attribute) der Tabelle. Ein Satellit kann entweder ein Kind einer Hub- oder einer Link-Tabelle sein.
In jeder dieser Tabellen wird ein Hash der Rohdaten des Schlüssels als Primärschlüssel der neuen Tabelle verwendet. Jede Tabelle enthält auch die Quelle der ursprünglichen Daten und einen Ladezeitstempel für die historische Verfolgung. Ein Satellit enthält auch einen Endzeitstempel und eine optionale Hash-Differenz zur Verfolgung von Änderungen an den Datensätzen.
Der Voracity Data Vault Generator Wizard verwendet die vorhandenen Primär- (PK) und Fremdschlüssel (FK) als Ausgangspunkt für die Organisation der neuen Tabellen. Die Standardwerte pro Tabelle sind wie folgt:
- Ein Knotenpunkt für jeden PK-Schlüssel (einschließlich zusammengesetzter Schlüssel).
- Ein Link für jeden selbstreferenzierenden FK.
- Ein Link für jede Gruppe von FKs (ohne die selbstreferenzierenden Schlüssel).
- Ein Satellit auf dem Hub, wenn die Tabelle null FKs enthält.
- Ein Satellit auf dem Link, wenn mindestens ein FK existiert.
In diesem Beispiel werden sieben verknüpfte Tabellen verwendet, die Personaldaten darstellen. Nachfolgend finden Sie das ERD für die Quelltabellen.
Zusammenfassung: Der Data Vault Generator in IRI Workbench automatisiert den Prozess des Prototyping eines neuen Data Vault-Projekts. Durch die Verwendung von Regeln können zufällig generierte, aber realistische und referenziell korrekte Testdaten verfeinert werden.
Nach dem Laden der Tabellenvorgaben können die Business Keys und deren Reihenfolge bearbeitet werden. Außerdem erstellt der Job die neuen Ressourcen, erzeugt den Zeitstempel, verkettet und hasht die Schlüsselfelder und lädt die neuen Ressourcen.
International bekannte Kunden seit 1978: Die NASA, American Airlines, Walt Disney, Comcast, Universal Music, Reuters, das Kraftfahrtbundesamt, das Bundeskriminalamt, die Bundesagentur für Arbeit, Rolex, Commerzbank, Lufthansa, Mercedes Benz, Osram und viele mehr setzen seit über 40 Jahren auf unsere Software für Big Data Wrangling und Datenschutz. Eine umfassende Liste unserer weltweiten Referenzen finden Sie hier, und speziell deutsche Referenzen finden Sie hier.
Partnerschaft mit IRI seit 1993: Durch die langjährige Zusammenarbeit mit Innovative Routines International Inc. aus Florida USA haben wir unser Produktportfolio um erstklassige Produkte wie IRI CoSort, IRI Voracity, IRI DarkShield, IRI FieldShield, IRI RowGen, IRI NextForm, IRI FACT und IRI CellShield erweitert. Die exklusiven Vertriebsrechte für diese Produkte in Deutschland liegen ausschließlich bei der JET-Software GmbH. Weitere Informationen zu unserem Partnerunternehmen IRI Inc. finden Sie hier.
JET-Software wurde 1986 gegründet und ist ein unabhängiger Softwareanbieter (ISV), der sich auf Hochleistungs-Datenmanagement und gezielte Datensicherheit spezialisiert hat. Die preisgekrönten, hochmodernen Big Data Lösungen werden von autorisierten Dienstleistern in mehr als 40 Städten weltweit unterstützt und helfen Kunden in jeder Branche:
Datentransformation und Datenintegration von Big Data ohne neue Hardware oder Fabrics
Schnellste Datenbank-Entlade-, Lade-, Reorg-, Abfrage- und Replikationsaufträge
Abbilden, Replizieren und Neuformatieren (Datenmigration) von Legacy-Datenbanken, Dateien und Datentypen
Erstellen von benutzerdefinierten Reports oder Aufbereiten von Daten für Ihr BI-/Analyse-Tools
Auffinden, Klassifizieren und De-Identifizieren von PII zur Einhaltung von HIPAA, PCI DSS, GDPR usw.
Generierung strukturell und referenziell korrekter Testdaten ohne Produktionsdaten
Statische, dynamische und inkrementelle Datenmaskierung (Echtzeitaktualisierung)
Beschleunigung oder Ersetzen von alten ETL-, JCL-, Shell-, SQL- und Sortierprogrammen
Erstellung und Verwaltung von Metadaten für strukturierte, semistrukturierte und unstrukturierte Daten
Die spezifischen Lösungen sind kompatibel mit allen gängigen Betriebssystemen, vom Mainframe (Fujitsu BS2000/OSD, IBM z/OS und z/VSE + z/Linux) bis hin zu Open Systems (UNIX & Derivate, Linux + Windows).
Zu unseren langjährigen Referenzen zählen deutsche Bundes- und Landesbehörden, Sozial- und Privatversicherungen, Landes-, Privat- und Großbanken, nationale und internationale Dienstleister, der Mittelstand sowie Großunternehmen.
JET-Software GmbH
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: +49 (6073) 711403
Fax: +49 (6073) 711405
E-Mail: amadeus.thomas@jet-software.com
![]()